Example 2: Sensitivity analysis for a NetLogo model with SALib and ipyparallel¶
This provides a more advanced example of interaction between NetLogo and a Python environment, using the SALib library (Herman & Usher, 2017); available through the pip package manager) to sample and analyze a suitable experimental design for a Sobol global sensitivity analysis. Furthermore, the ipyparallel package (also available on pip) is used to parallelize the simulations.
All files used in the example are available from the pyNetLogo repository at https://github.com/quaquel/pyNetLogo.
[1]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("white")
sns.set_context("talk")
import pynetlogo
# Import the sampling and analysis modules for a Sobol variance-based
# sensitivity analysis
from SALib.sample import sobol as sobolsample
from SALib.analyze import sobol
SALib relies on a problem definition dictionary which contains the number of input parameters to sample, their names (which should here correspond to a NetLogo global variable), and the sampling bounds. Documentation for SALib can be found at https://salib.readthedocs.io/en/latest/.
[2]:
problem = {
"num_vars": 6,
"names": [
"random-seed",
"grass-regrowth-time",
"sheep-gain-from-food",
"wolf-gain-from-food",
"sheep-reproduce",
"wolf-reproduce",
],
"bounds": [
[1, 100000],
[20.0, 40.0],
[2.0, 8.0],
[16.0, 32.0],
[2.0, 8.0],
[2.0, 8.0],
],
}
The SALib sampler will automatically generate an appropriate number of samples for Sobol analysis, using a revised Saltelli sampling sequence. To calculate first-order, second-order and total sensitivity indices, this gives a sample size of n(2p+2), where p is the number of input parameters, and n is a baseline sample size which should be large enough to stabilize the estimation of the indices. For this example, we use n = 1000, for a total of 14000 experiments.
[3]:
n = 1024
param_values = sobolsample.sample(problem, n, calc_second_order=True)
The sampler generates an input array of shape (n(2p+2), p) with rows for each experiment and columns for each input parameter.
[4]:
param_values.shape
[4]:
(14336, 6)
Running the experiments in parallel using ipyparallel¶
Ipyparallel is a standalone package (available through the pip package manager) which can be used to interactively run parallel tasks from IPython on a single PC, but also on multiple computers. On machines with multiple cores, this can significantly improve performance: for instance, the multiple simulations required for a sensitivity analysis are easy to run in parallel. Documentation for Ipyparallel is available at http://ipyparallel.readthedocs.io/en/latest/intro.html.
Ipyparallel first requires starting a controller and multiple engines, which can be done from a terminal or command prompt, or conveniently from within a notebook.
[5]:
import ipyparallel as ipp
cluster = ipp.Cluster(n=4)
cluster.start_cluster_sync();
Starting 4 engines with <class 'ipyparallel.cluster.launcher.LocalEngineSetLauncher'>
Next, we can connect the interactive notebook to the started cluster by instantiating a client, and checking that client.ids returns a list of 4 available engines.
[7]:
rc = cluster.connect_client_sync()
rc.wait_for_engines(n=4)
rc.ids
[7]:
[0, 1, 2, 3]
With the client setup, we can now interact with the cluster. We can for example get a direct view of all engines in the cluster.
[8]:
direct_view = rc[:]
[9]:
import os
# Push the current working directory of the notebook to a "cwd" variable on the engines that can be accessed later
direct_view.push(dict(cwd=os.getcwd()), block=True)
[9]:
[None, None, None, None]
[10]:
# Push the "problem" variable from the notebook to a corresponding variable on the engines
direct_view.push(dict(problem=problem), block=True)
[10]:
[None, None, None, None]
The %%px command can be added to a notebook cell to run it in parallel on each of the engines. Here the code first involves some imports and a change of the working directory. We then start a link to NetLogo, and load the example model on each of the engines.
[12]:
%%px
import os
os.chdir(cwd) # pushed to all workers via direct_View.push
import pynetlogo
import pandas as pd
netlogo = pynetlogo.NetLogoLink(gui=False)
netlogo.load_model('./models/Wolf Sheep Predation_v6.nlogo')
We can then use the IPyparallel map functionality to run the sampled experiments, now using a “load balanced” view to automatically handle the scheduling and distribution of the simulations across the engines. This is for instance useful when simulations may take different amounts of time.
We first set up a simulation function that takes a single experiment (i.e. a vector of input parameters) as an argument, and returns the outcomes of interest in a pandas Series.
[13]:
def simulation(experiment):
# Set the input parameters
for i, name in enumerate(problem["names"]):
if name == "random-seed":
# The NetLogo random seed requires a different syntax
netlogo.command("random-seed {}".format(experiment[i]))
else:
# Otherwise, assume the input parameters are global variables
netlogo.command("set {0} {1}".format(name, experiment[i]))
netlogo.command("setup")
# Run for 100 ticks and return the number of sheep and wolf agents at each time step
counts = netlogo.repeat_report(["count sheep", "count wolves"], 100)
results = pd.Series(
[np.mean(counts["count sheep"]), np.mean(counts["count wolves"])],
index=["Avg. sheep", "Avg. wolves"],
)
return results
We then create a load balanced view and run the simulation with the map_sync method. This method takes a function and a Python sequence as arguments, applies the function to each element of the sequence, and returns results once all computations are finished.
In this case, we pass the simulation function and the array of experiments (param_values), so that the function will be executed for each row of the array.
The DataFrame constructor is then used to immediately build a DataFrame from the results (which are returned as a list of Series). The to_csv method provides a simple way of saving the results to disk; pandas supports several more advanced storage options, such as serialization with msgpack, or hierarchical HDF5 storage.
[15]:
lview = rc.load_balanced_view()
results = pd.DataFrame(lview.map_sync(simulation, param_values))
[16]:
results.to_csv("./data/Sobol_parallel.csv")
[17]:
results.head(5)
[17]:
| Avg. sheep | Avg. wolves | |
|---|---|---|
| 0 | 106.861386 | 82.128713 |
| 1 | 109.465347 | 65.158416 |
| 2 | 106.861386 | 82.128713 |
| 3 | 133.267327 | 154.594059 |
| 4 | 129.297030 | 45.990099 |
Using SALib for sensitivity analysis¶
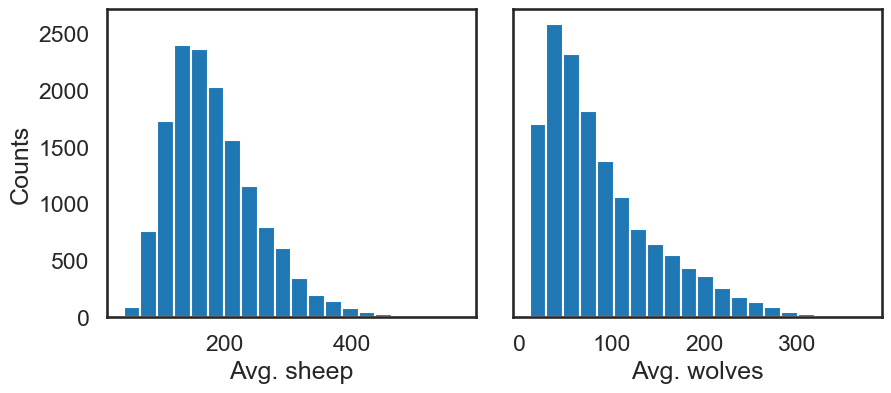
We can then proceed with the analysis, first using a histogram to visualize output distributions for each outcome:
[18]:
fig, ax = plt.subplots(1, len(results.columns), sharey=True)
for i, n in enumerate(results.columns):
ax[i].hist(results[n], 20)
ax[i].set_xlabel(n)
ax[0].set_ylabel("Counts")
fig.set_size_inches(10, 4)
fig.subplots_adjust(wspace=0.1)
plt.show()
Bivariate scatter plots can be useful to visualize relationships between each input parameter and the outputs. Taking the outcome for the average sheep count as an example, we obtain the following, using the scipy library to calculate the Pearson correlation coefficient (r) for each parameter, and the seaborn library to plot a linear trend fit.
[21]:
import scipy
nrow = 2
ncol = 3
fig, ax = plt.subplots(nrow, ncol, sharey=True)
y = results["Avg. sheep"]
for i, a in enumerate(ax.flatten()):
x = param_values[:, i]
sns.regplot(
x=x,
y=y,
ax=a,
ci=None,
color="k",
scatter_kws={"alpha": 0.2, "s": 4, "color": "gray"},
)
pearson = scipy.stats.pearsonr(x, y)
a.annotate(
"r: {:6.3f}".format(pearson[0]),
xy=(0.15, 0.85),
xycoords="axes fraction",
fontsize=13,
)
if divmod(i, ncol)[1] > 0:
a.get_yaxis().set_visible(False)
a.set_xlabel(problem["names"][i])
a.set_ylim([0, 1.1 * np.max(y)])
fig.set_size_inches(9, 9, forward=True)
fig.subplots_adjust(wspace=0.2, hspace=0.3)
plt.show()
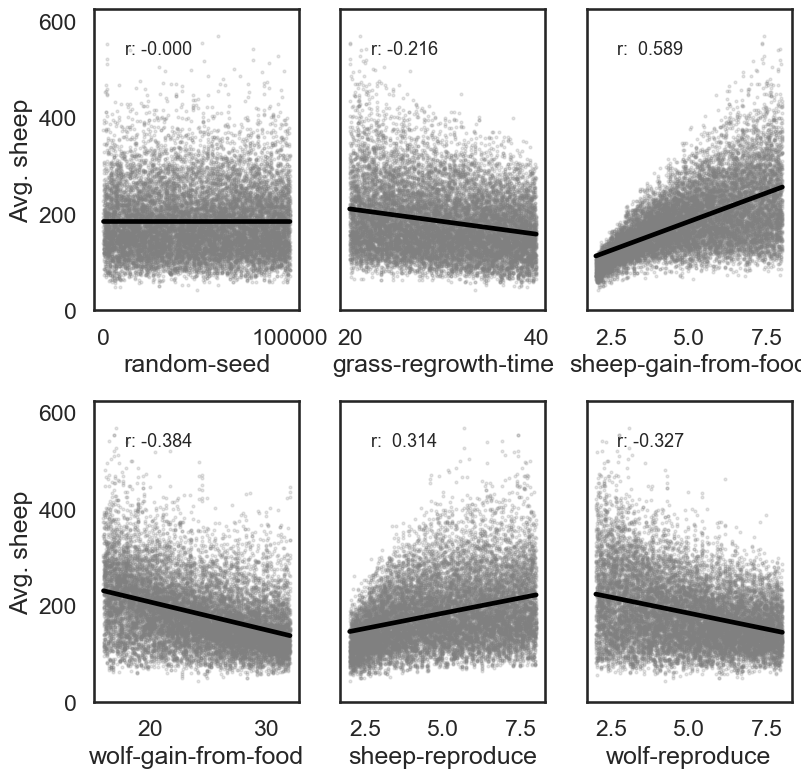
This indicates a positive relationship between the “sheep-gain-from-food” parameter and the mean sheep count, and negative relationships for the “wolf-gain-from-food” and “wolf-reproduce” parameters.
We can then use SALib to calculate first-order (S1), second-order (S2) and total (ST) Sobol indices, to estimate each input’s contribution to output variance as well as input interactions (again using the mean sheep count). By default, 95% confidence intervals are estimated for each index.
[22]:
Si = sobol.analyze(
problem,
results["Avg. sheep"].values,
calc_second_order=True,
print_to_console=False,
)
As a simple example, we first select and visualize the total and first-order indices for each input, converting the dictionary returned by SALib to a DataFrame. The default pandas plotting method is then used to plot these indices along with their estimated confidence intervals (shown as error bars).
[23]:
Si_filter = {k: Si[k] for k in ["ST", "ST_conf", "S1", "S1_conf"]}
Si_df = pd.DataFrame(Si_filter, index=problem["names"])
[24]:
Si_df
[24]:
| ST | ST_conf | S1 | S1_conf | |
|---|---|---|---|---|
| random-seed | 0.050776 | 0.006568 | -0.004114 | 0.017626 |
| grass-regrowth-time | 0.111551 | 0.016164 | 0.032316 | 0.030256 |
| sheep-gain-from-food | 0.543193 | 0.067641 | 0.359385 | 0.062889 |
| wolf-gain-from-food | 0.225840 | 0.028651 | 0.152584 | 0.045471 |
| sheep-reproduce | 0.243577 | 0.034768 | 0.142665 | 0.044973 |
| wolf-reproduce | 0.240973 | 0.039485 | 0.108223 | 0.042038 |
[25]:
fig, ax = plt.subplots(1)
indices = Si_df[["S1", "ST"]]
err = Si_df[["S1_conf", "ST_conf"]]
indices.plot.bar(yerr=err.values.T, ax=ax)
fig.set_size_inches(8, 4)
plt.show()
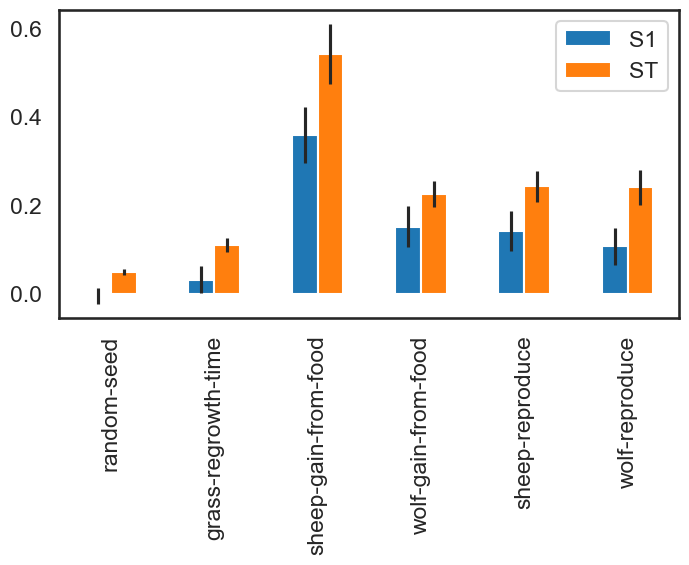
The “sheep-gain-from-food” parameter has the highest ST index, indicating that it contributes over 50% of output variance when accounting for interactions with other parameters. However, it can be noted that confidence bounds are still quite broad with this sample size, particularly for the S1 index (which indicates each input’s individual contribution to variance).
We can use a more sophisticated visualization to include the second-order interactions between inputs estimated from the S2 values.
[30]:
%matplotlib inline
import itertools
from math import pi
def normalize(x, xmin, xmax):
return (x - xmin) / (xmax - xmin)
def plot_circles(ax, locs, names, max_s, stats, smax, smin, fc, ec, lw, zorder):
s = np.asarray([stats[name] for name in names])
s = 0.01 + max_s * np.sqrt(normalize(s, smin, smax))
fill = True
for loc, name, si in zip(locs, names, s):
if fc == "w":
fill = False
else:
ec = "none"
x = np.cos(loc)
y = np.sin(loc)
circle = plt.Circle(
(x, y),
radius=si,
ec=ec,
fc=fc,
transform=ax.transData._b,
zorder=zorder,
lw=lw,
fill=True,
)
ax.add_artist(circle)
def filter(sobol_indices, names, locs, criterion, threshold):
if criterion in ["ST", "S1", "S2"]:
data = sobol_indices[criterion]
data = np.abs(data)
data = data.flatten() # flatten in case of S2
# TODO:: remove nans
filtered = [(name, locs[i]) for i, name in enumerate(names) if data[i] > threshold]
filtered_names, filtered_locs = zip(*filtered)
elif criterion in ["ST_conf", "S1_conf", "S2_conf"]:
raise NotImplementedError
else:
raise ValueError("unknown value for criterion")
return filtered_names, filtered_locs
def plot_sobol_indices(sobol_indices, criterion="ST", threshold=0.01):
"""plot sobol indices on a radial plot
Parameters
----------
sobol_indices : dict
the return from SAlib
criterion : {'ST', 'S1', 'S2', 'ST_conf', 'S1_conf', 'S2_conf'}, optional
threshold : float
only visualize variables with criterion larger than cutoff
"""
max_linewidth_s2 = 15 # 25*1.8
max_s_radius = 0.3
# prepare data
# use the absolute values of all the indices
# sobol_indices = {key:np.abs(stats) for key, stats in sobol_indices.items()}
# dataframe with ST and S1
sobol_stats = {key: sobol_indices[key] for key in ["ST", "S1"]}
sobol_stats = pd.DataFrame(sobol_stats, index=problem["names"])
smax = sobol_stats.max().max()
smin = sobol_stats.min().min()
# dataframe with s2
s2 = pd.DataFrame(sobol_indices["S2"], index=problem["names"], columns=problem["names"])
s2[s2 < 0.0] = 0.0 # Set negative values to 0 (artifact from small sample sizes)
s2max = s2.max().max()
s2min = s2.min().min()
names = problem["names"]
n = len(names)
ticklocs = np.linspace(0, 2 * pi, n + 1)
locs = ticklocs[0:-1]
filtered_names, filtered_locs = filter(sobol_indices, names, locs, criterion, threshold)
# setup figure
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.grid(False)
ax.spines["polar"].set_visible(False)
ax.set_xticks(locs)
ax.set_xticklabels(names)
ax.set_yticklabels([])
ax.set_ylim(top=1.4)
legend(ax)
# plot ST
plot_circles(
ax,
filtered_locs,
filtered_names,
max_s_radius,
sobol_stats["ST"],
smax,
smin,
"w",
"k",
1,
9,
)
# plot S1
plot_circles(
ax,
filtered_locs,
filtered_names,
max_s_radius,
sobol_stats["S1"],
smax,
smin,
"k",
"k",
1,
10,
)
# plot S2
for name1, name2 in itertools.combinations(zip(filtered_names, filtered_locs), 2):
name1, loc1 = name1
name2, loc2 = name2
weight = s2.loc[name1, name2]
lw = 0.5 + max_linewidth_s2 * normalize(weight, s2min, s2max)
ax.plot([loc1, loc2], [1, 1], c="darkgray", lw=lw, zorder=1)
return fig
from matplotlib.legend_handler import HandlerPatch
class HandlerCircle(HandlerPatch):
def create_artists(
self, legend, orig_handle, xdescent, ydescent, width, height, fontsize, trans
):
center = 0.5 * width - 0.5 * xdescent, 0.5 * height - 0.5 * ydescent
p = plt.Circle(xy=center, radius=orig_handle.radius)
self.update_prop(p, orig_handle, legend)
p.set_transform(trans)
return [p]
def legend(ax):
some_identifiers = [
plt.Circle((0, 0), radius=5, color="k", fill=False, lw=1),
plt.Circle((0, 0), radius=5, color="k", fill=True),
plt.Line2D([0, 0.5], [0, 0.5], lw=8, color="darkgray"),
]
ax.legend(
some_identifiers,
["ST", "S1", "S2"],
loc=(1, 0.75),
borderaxespad=0.1,
mode="expand",
handler_map={plt.Circle: HandlerCircle()},
)
sns.set_style("whitegrid")
fig = plot_sobol_indices(Si, criterion="ST", threshold=0.005)
fig.set_size_inches(7, 7)
plt.show()
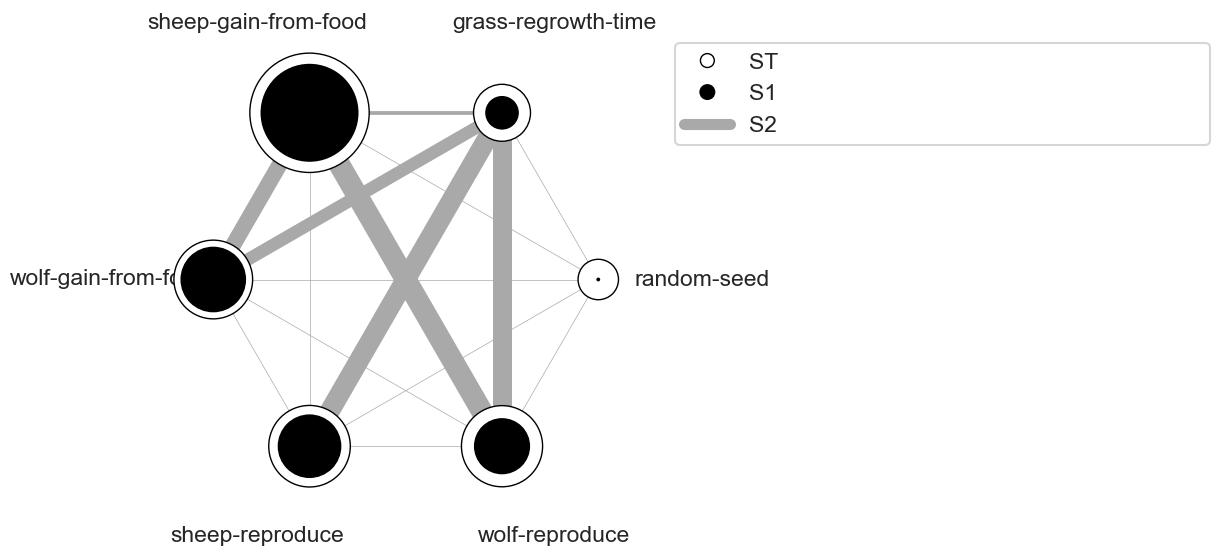
In this case, the “sheep-gain-from-food” variable has strong interactions with the “wolf-gain-from-food” and “wolf-reproduce” inputs in particular. The size of the ST and S1 circles correspond to the normalized variable importances.
[ ]: